Recommender System
Author: Hao Zheng
While we talk about marketing, most of us will think about the diverse ads on the television. However, in real world, marketing is everywhere. Especially with the help from programming languages, advertisement can reach all corners of your life in an easier way without letting you notice it. For example, personizing the replying message so that customers feel connected.
In this project, we will lead you through a combination of text processing and marketing that mainly focus on the content optimization aspect: the recommender system and let you understand how the system actually works. We encourage you to create your own Jupytor notebook and follow along. You can also download this notebook together with any affiliated data in the Notebooks and Data GitHub repository. Alternatively, if you do not have Python or Jupyter Notebook installed yet, you may experiment with a virtual notebook by launching Binder or Syzygy below (learn more about these two tools in the Resource tab).
Business Problem
Here we can use the movie industry as an example to illustrate how the recommender system can actually be applied into a business context. The traditional movie content provider systems don’t care about the general taste of the customers because how they get their revenue is irrelevant to their ability to tell their customers’ taste. On the other words, the traditional movie seller only focus on the most welcomed movie and try to sell as many as possible. However, with the introduction of the age of internet, how current movie sellers makes money actually changes. Their income is now highly correlated with how long custoemrs spend on the site to watch the movie. So here the recommender system is required to make sure customers got the best recommendation and spend more time on the website.
We will use the movie rating dataset to try to duplicate that process.
# Import the packages and read in the data
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df1=pd.read_csv('data/tmdb_5000_credits.csv')
df2=pd.read_csv('data/tmdb_5000_movies.csv')
Explore the data
The data is clean so here we do not want to go through the cleaning process again. But it is still useful to look at the data before starting to play around with it.
# Explore the column names to find out what is in the dataframe
print("The first dataframe includes the information about: " )
for i in df1.columns: print(i, end =", ")
print("\nThe second dataframe includes the information about: ")
for i in df2.columns: print(i, end =", ")
The first dataframe includes the information about:
movie_id, title, cast, crew,
The second dataframe includes the information about:
budget, genres, homepage, id, keywords, original_language, original_title, overview, popularity, production_companies, production_countries, release_date, revenue, runtime, spoken_languages, status, tagline, title, vote_average, vote_count,
The first dataframe includes four different columns the reflects on the general production information about the movie whereas the second dataframe includes detailed information like genres and popularity. We can see that both dataset includes the unique identifier for the movie, so we can try to combine two datasets for simplicities.
# Change the columns name to id so it is ready to merge
df1.columns = ['id','tittle','cast','crew']
# Merge two dataset on the unique identifier
new_df= pd.merge(df1,df2,on='id')
new_df.head(2)
| id | tittle | cast | crew | budget | genres | homepage | keywords | original_language | original_title | ... | production_countries | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 19995 | Avatar | [{"cast_id": 242, "character": "Jake Sully", "... | [{"credit_id": "52fe48009251416c750aca23", "de... | 237000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://www.avatarmovie.com/ | [{"id": 1463, "name": "culture clash"}, {"id":... | en | Avatar | ... | [{"iso_3166_1": "US", "name": "United States o... | 2009-12-10 | 2787965087 | 162.0 | [{"iso_639_1": "en", "name": "English"}, {"iso... | Released | Enter the World of Pandora. | Avatar | 7.2 | 11800 |
| 1 | 285 | Pirates of the Caribbean: At World's End | [{"cast_id": 4, "character": "Captain Jack Spa... | [{"credit_id": "52fe4232c3a36847f800b579", "de... | 300000000 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | http://disney.go.com/disneypictures/pirates/ | [{"id": 270, "name": "ocean"}, {"id": 726, "na... | en | Pirates of the Caribbean: At World's End | ... | [{"iso_3166_1": "US", "name": "United States o... | 2007-05-19 | 961000000 | 169.0 | [{"iso_639_1": "en", "name": "English"}] | Released | At the end of the world, the adventure begins. | Pirates of the Caribbean: At World's End | 6.9 | 4500 |
2 rows × 23 columns
Building Recommender System
Method 1: Demographic Filtering
This is the fundamental method that we will try to use here. In this method, we are giving users movie recommendation based on the genre of the movie. Generally, the movie with higher popularity will be liked by more people. So what we need to do this method is: 1. Find out a scientific way to reflect the popularity of the movie 2.Recommend the most popular movie.
The two major factors that we are using here will be vote_average and the vote_count. Vote average reflects the overall opinion whereas the vote count reflect how accurate the average score is. There are countless way to calculate for the “real” score, so feel free to think about your own method.
The final score calculation that we would use here would be:
average vote score + (vote score of selected film - average vote score) * ((vote count of selected film - average vote count)/average vote count) ^ 2
# Define the method to calculate the score:
am = new_df['vote_average'].mean()
bm = new_df['vote_count'].mean()
def rating(x):
a = x['vote_average']
b = x['vote_count']
return am + (a - am)* ((b - bm)/bm) ** 2
# Apply the function to the entire dataframe
## Create a new df for method 1
new_df1 = new_df.copy()
new_df1['score_cal'] = new_df.apply(rating,axis = 1)
new_df1.head(2)
| id | tittle | cast | crew | budget | genres | homepage | keywords | original_language | original_title | ... | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | score_cal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 19995 | Avatar | [{"cast_id": 242, "character": "Jake Sully", "... | [{"credit_id": "52fe48009251416c750aca23", "de... | 237000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://www.avatarmovie.com/ | [{"id": 1463, "name": "culture clash"}, {"id":... | en | Avatar | ... | 2009-12-10 | 2787965087 | 162.0 | [{"iso_639_1": "en", "name": "English"}, {"iso... | Released | Enter the World of Pandora. | Avatar | 7.2 | 11800 | 293.111430 |
| 1 | 285 | Pirates of the Caribbean: At World's End | [{"cast_id": 4, "character": "Captain Jack Spa... | [{"credit_id": "52fe4232c3a36847f800b579", "de... | 300000000 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | http://disney.go.com/disneypictures/pirates/ | [{"id": 270, "name": "ocean"}, {"id": 726, "na... | en | Pirates of the Caribbean: At World's End | ... | 2007-05-19 | 961000000 | 169.0 | [{"iso_639_1": "en", "name": "English"}] | Released | At the end of the world, the adventure begins. | Pirates of the Caribbean: At World's End | 6.9 | 4500 | 30.704168 |
2 rows × 24 columns
# Print out the top five films
new_df1 = new_df1.sort_values('score_cal', ascending=False)
new_df1[['title', 'score_cal']].head(5)
| title | score_cal | |
|---|---|---|
| 96 | Inception | 725.141884 |
| 65 | The Dark Knight | 572.233379 |
| 95 | Interstellar | 442.582874 |
| 662 | Fight Club | 358.708821 |
| 16 | The Avengers | 343.465619 |
# Visualize the result
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.bar(new_df1['title'][0:5],new_df1['score_cal'][0:5])
plt.grid(True)
plt.show()
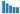
Based on the calculated results, we will be able to recomend Inception, The Dark Knight, Intersetllar, Fight Club and The Avengers to all the people because these are the most welcomed popular movies.
However, This is not an ideal way of making a recommender system because there is no personalized recommendation in it. All the people will receive the same recommendation no matter which type of genres they prefer. So we might want to try on a different method to include personal preference into our system.
Method 2: Content Based Filtering
This method will not focus on recommending similar film based on personal taste. Which means, if you just watched an action movie with english subtitle, the next movie recommended for you is likely to be another action moview with english subtitle. I will show you how to build such a system.
In this recommender system, I will use genres and keywords to help me find out similar films. In the dataset, the both genres and keywords are stored as string value, so we need to do some text extraction before moving to next step.
# Extract important words form selected_columns
from ast import literal_eval
new_df2 = new_df.copy()
selected_columns = ["genres","keywords"]
for feature in selected_columns:
new_df2[feature] = new_df2[feature].apply(literal_eval)
# Return the top 3 elements/entire list(if there are less than 3 elements) and change all element to low case
## Reference:
## https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system/#Content-Based-Filtering
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
return []
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
# Apply the defined method so it is ready for further processing
for feature in selected_columns:
new_df2[feature] = new_df2[feature].apply(get_list)
for feature in selected_columns:
new_df2[feature] = new_df2[feature].apply(clean_data)
In the next step, we use the cosines similarity to find which movies to recommend. On the other hand, the cosines similarity is the new score we use in this second method.
# Concat the two feature together
for i, r in new_df2.iterrows():
new_df2['test'][i] = " ".join(new_df2["genres"][i]) + " ".join(new_df2["keywords"][i])
# Use Vectorizer to change words into matrix
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(new_df2['test'])
# Introduce cosines similarity
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix)
/Users/haozheng/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
after removing the cwd from sys.path.
#Construct a reverse map of indices and movie titles
indices = pd.Series(new_df2.index, index=new_df2['title']).drop_duplicates()
# Use the cosines similarity to find out which movies to recommend
def get_recom(title,cosine_sim):
# Get the index of the movie that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
return df2['title'].iloc[movie_indices]
get_recom('Avatar', cosine_sim2)
85 Captain America: The Winter Soldier
2444 Damnation Alley
71 The Mummy: Tomb of the Dragon Emperor
83 The Lovers
518 Inspector Gadget
600 Killer Elite
678 Dragon Blade
786 The Monkey King 2
1273 Extreme Ops
1324 Virgin Territory
Name: title, dtype: object
Here we have the recommending list that is based on user’s preference. This is going to perform way better than the first method. However, we can still continue to improve it.
Next Step
Apart from these two method, there is a third way out there which is called the collaborative filtering which combines content based filtering and demographic filtering. In this method, you can combine the result from two methods giving different weights to them.
For example, if avater is the 4th movie using content based filtering and the 20th movie using demographic filtering in a database the consist of 100 movies. We can generate a new score with reverse ranking method if two method have same weights in our calculation:
0.5 _ (100 - 4) + 0.5 _ (100 - 20)
We can use the new score to rank the movie again just like we did in demographic filtering method.
Can you try to do it yourself?
Reference
https://www.kaggle.com/tmdb/tmdb-movie-metadata
https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system/?select=tmdb_5000_movies.csv